

Learning materials

Download the EUCLID iBook
Each chapter of this book is targeting a different crucial task related to Linked Data. You will have the opportunity to study in depth various aspects of the usage of Linked Data, watch webinar movies and screencasts, as well as test your knowledge via quizzes and exercises.
![]()
If you don't have access to the Apple iBooks Store in your country,
you can download it from here (size: 570MB).
Study our modules
The EUCLID modules consist of a series of eBook chapters and online courses covering all major aspects of the Linked Data consumption lifecycle.
The EUCLID eBook chapters contain multimedia materials, such as videos and screencasts, as well as quizzes. They are available for the following platforms:
- Web browsers (HTML)
- iPad & MacOS (iBook)
- eReaders (ePUB)
- Kindle devices
The EUCLID online courses provide an integrated overview, structured as a learning pathway, of all the learning materials produced in the project. You can study these courses at your own pace, as there is no predetermined start or end date. They are available for:
- Web browsers (HTML)
- iPad, iPhone and iPod touch (iTunes U)
-
Module 1: Introduction and Application Scenarios
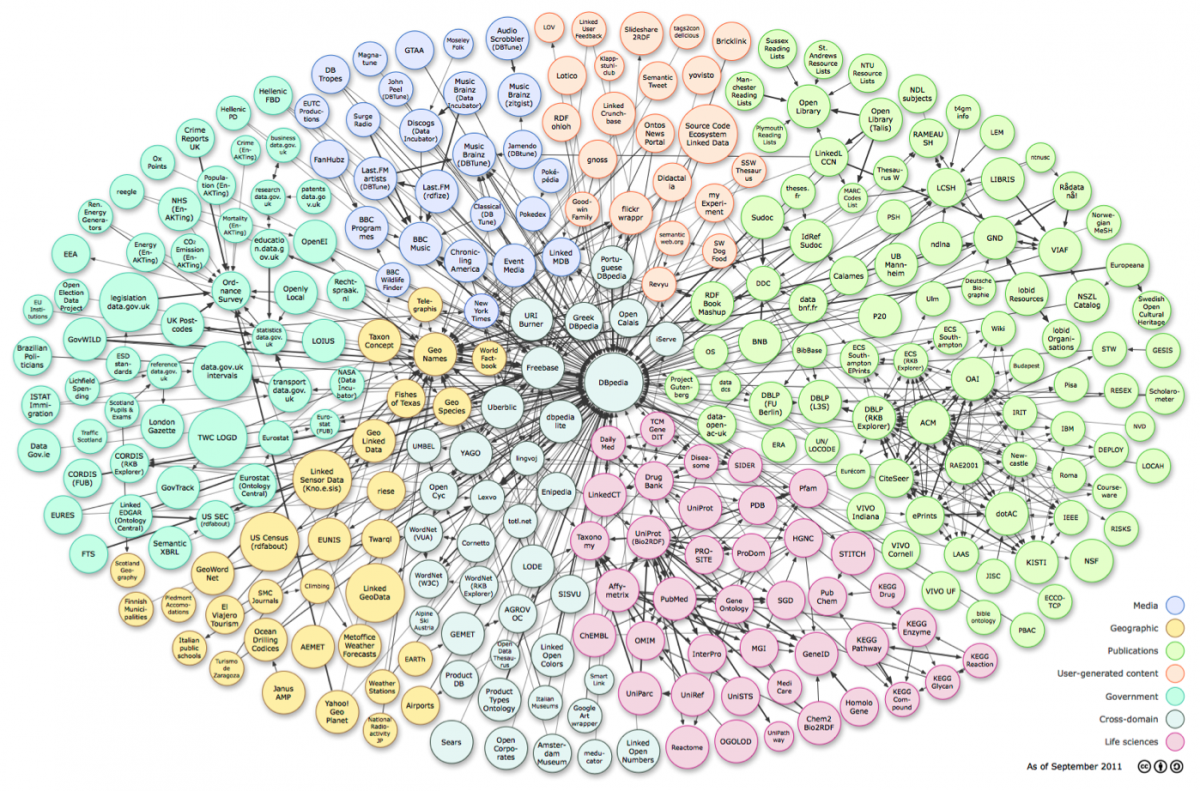
This module introduces the main principles of Linked Data, the underlying technologies and background standards. It provides basic knowledge for how data can be published over the Web, how it can be queried, and what are the possible use cases and benefits. As an example, we use the development of a music portal (based on the MusicBrainz dataset), which facilitates access to a wide range of information and multimedia resources relating to music. The module also includes some multiple choice questions in the form of a quiz, screencasts of popular tools and embedded videos.
Course (includes screencasts and exercises)
-
Module 2: Querying Linked Data
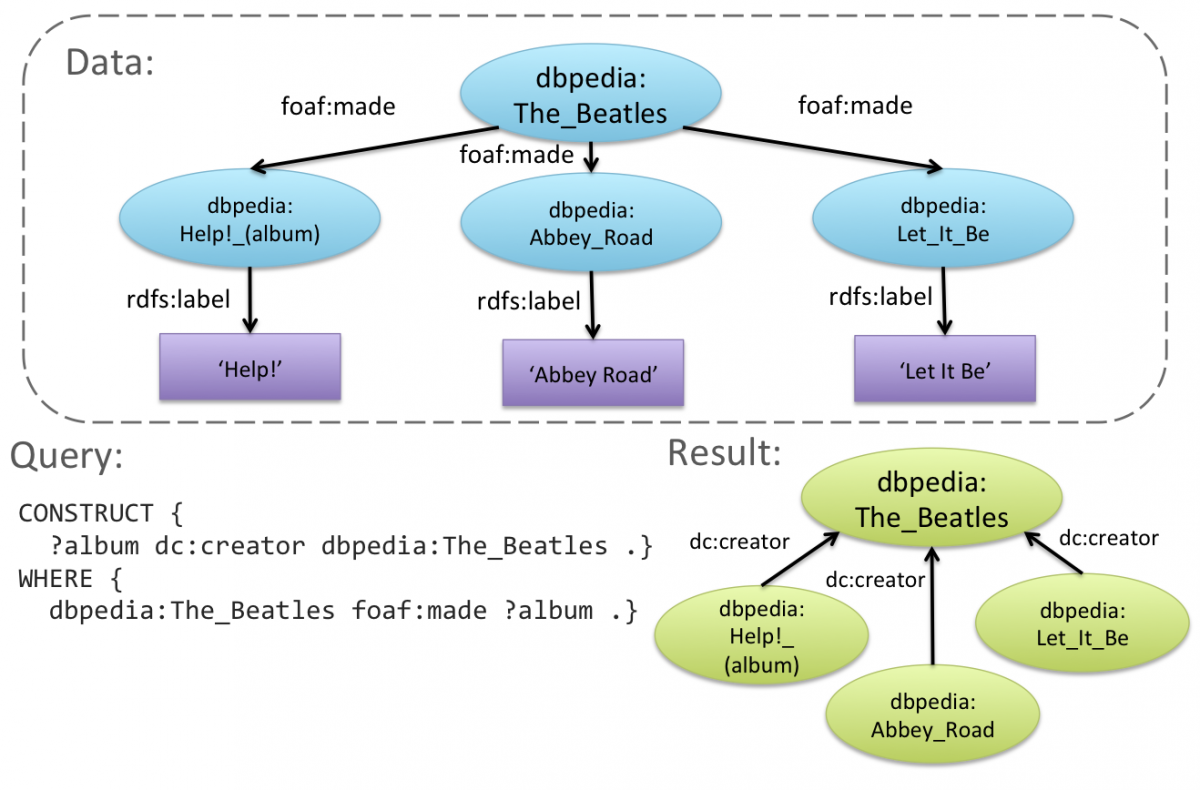
This module looks in detail at SPARQL (SPARQL Protocol and RDF Query Language) and introduces approaches for querying and updating semantic data. It covers the SPARQL algebra, the SPARQL protocol, and provides examples for reasoning over Linked Data. The module uses examples from the music domain, which can be directly tried out and ran over the MusicBrainz dataset. This includes gaining some familiarity with the RDFS and OWL languages, which allow developers to formulate generic and conceptual knowledge that can be exploited by automatic reasoning services in order to enhance the power of querying.
Course (includes screencasts and exercises)
-
Module 3: Providing Linked Data
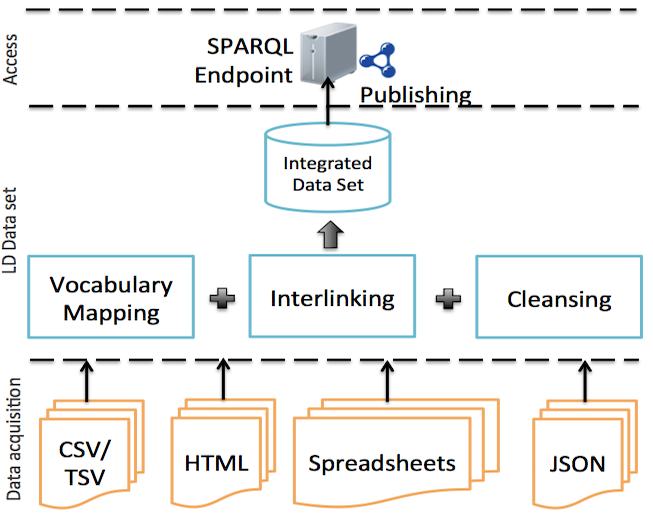
This module covers the whole spectrum of Linked Data production and exposure. After a grounding in the Linked Data principles and best practices, with special emphasis on the VoID vocabulary, we cover R2RML, operating on relational databases, Open Refine, operating on spreadsheets, and GATECloud, operating on natural language. Finally we describe the means to increase interlinkage between datasets, especially the use of tools like Silk.
Course (includes screencasts and exercises)
-
Module 4: Interaction with Linked Data
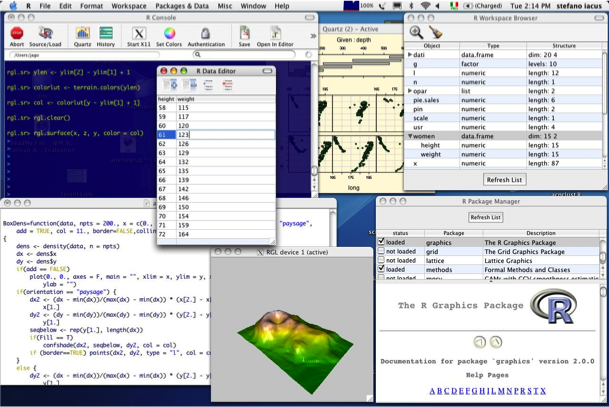
This module focuses on providing means for exploring Linked Data. In particular, it gives an overview of current visualization tools and techniques, looking at semantic browsers and applications for presenting the data to the end used. We also describe existing search options, including faceted search, concept-based search and hybrid search, based on a mix of using semantic information and text processing. Finally, we conclude with approaches for Linked Data analysis, describing how available data can be synthesized and processed in order to draw conclusions. The module includes a number of practical examples with available tools as well as an extensive demo based on analyzing, visualizing and searching data from the music domain.
Course (includes screencasts and exercises)
-
Module 5: Creating Linked Data Applications
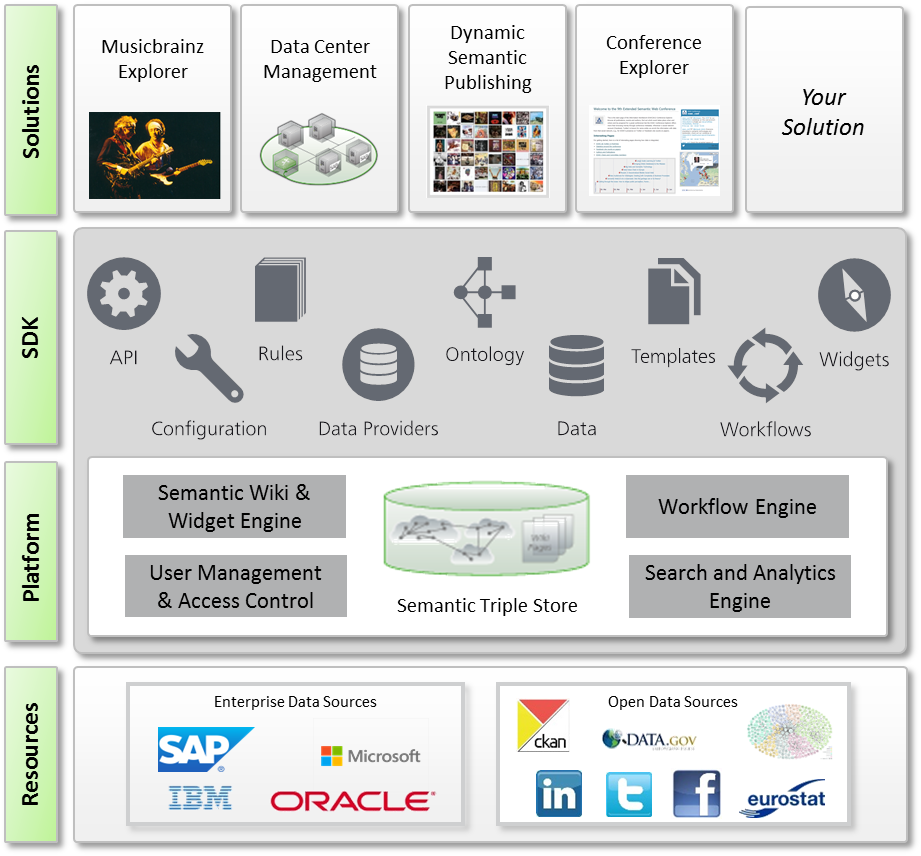
This module gives details on technologies and approaches towards exploiting Linked Data by building LD applications. In particular, it gives an overview of popular existing applications and introduces the main technologies that support implementation and development. Furthermore, it illustrates how data exposed through common Web APIs can be integrated with Linked Data in order to create mashups.
Course (includes screencasts and exercises)
-
Module 6: Scaling up
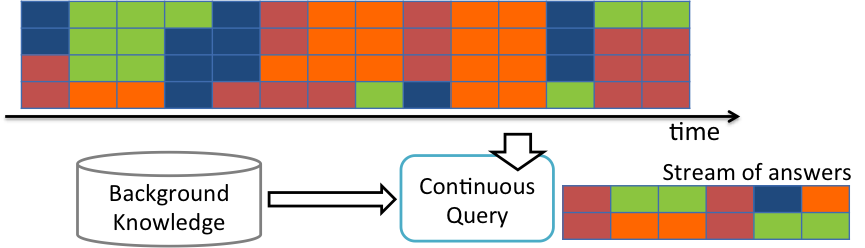
This module addresses the main issues of Linked Data and scalability. In particular, it provides details on approaches and technologies for clustering, distributing, sharing, and caching data. Furthermore, it addresses the means for publishing data and the relationship between Big Data and Linked Data, exploring how some of the solutions can be transferred in the context of Linked Data.
Course (includes screencasts and exercises)
Follow our learning pathways
The following table describes which Euclid training modules are most relevant for which data professional training. Naturally, the introductory and intermediate modules are suitable for all data expert types, even if certain topics might be more suitable for a given audience than others.
|
|
Data Architect |
Data Manager |
Data Analyst |
Data Application Developer |
|---|---|---|---|---|
|
Introductory Level |
||||
|
Intermediate Level
|
|
|||
|
|
|
|||
|
|
|
|
||
|
Advanced Level |
|
|
|
|
|
|
|
|

Add new comment